امنیت داکر: هر آنچه باید درباره مدل امنیتی زمان اجرا بدانید
مقدمه
امنیت کانتینرها در سالهای اخیر پیشرفت زیادی کرده، اما بسیاری از توصیههایی که هنوز درباره امنیت داکر میبینیم، متعلق به سالها قبل هستند.
اگر تا به حال دنبال بهترین روشهای امنیتی داکر گشته باشید، احتمالاً با توصیههایی مثل این مواجه شدهاید:
- کانتینر را با کاربر روت اجرا نکنید.
- قابلیتهای غیرضروری را حذف کنید.
- از فایلسیستم فقطخواندنی استفاده کنید.
- seccomp را فعال کنید.
- هرگز از
--privilegedاستفاده نکنید.
همه اینها توصیههای درستی هستند، اما مشکل اینجاست که معمولاً بهعنوان «قانون» مطرح میشوند، نه بهعنوان مفهومی که باید درکشان کرد.
اگر دنبال یک مرجع خوب برای بهترین روشهای امنیتی باشید، OWASP Docker Cheat Sheet یکی از بهترین گزینههاست. این مقاله روی همان پایه ساخته شده، با این تفاوت که مکانیزمهای امنیتی لینوکس پشت هر توصیه را توضیح میدهد: این مکانیزمها چه کاری انجام میدهند، اصلاً چرا وجود دارند، و چه معاوضههایی دارند. در پایان، نهتنها میدانید از کدام گزینههای امنیتی استفاده کنید، بلکه میفهمید چرا مهم هستند و کجا باید به کارشان ببرید.
خلاصه: این مقاله مدل امنیتی زمان اجرای داکر را پوشش میدهد: قابلیتهای لینوکس، seccomp، AppArmor، user namespaces، فایلسیستمهای فقطخواندنی، محدودیت منابع و امنیت دیمن. هر بخش یک مکانیزم خاص را توضیح میدهد، میگوید چرا مهم است و چطور در داکر، کامپوز و کوبرنتیز پیکربندی میشود. تمرکز اصلی روی محدود کردن کارهایی است که مهاجم بعد از بهدستآوردن اجرای کد در یک کانتینر تولید میتواند انجام دهد. امنیت زنجیره تأمین، اسرار و امنیت شبکه در این مقاله پوشش داده نمیشود.
مدل تهدید
قبل از اینکه برویم سراغ ویژگیهای امنیتی داکر، باید به یک سؤال ساده جواب بدهیم:
اصلاً از کی داریم دفاع میکنیم؟
توصیههای امنیتی فقط در چارچوب یک مدل تهدید معنا پیدا میکنند. یک کانتینر که روی ماشین توسعه شما اجرا میشود، الزامات امنیتی کاملاً متفاوتی با یک API تولیدی دارد که در معرض عموم قرار دارد.
در ادامه این مقاله، سناریوی زیر را در نظر میگیریم:
- یک برنامه تولیدی داخل یک کانتینر داکر اجرا میشود.
- این برنامه برای کاربران غیرقابلاعتماد از طریق شبکه قابل دسترسی است.
- به خاطر یک آسیبپذیری در برنامه، مهاجم موفق میشود از راه دور (RCE) در داخل کانتینر کد اجرا کند.
- مهاجم حالا میتواند هر دستوری را با همان سطح دسترسی فرآیند برنامه اجرا کند.
توجه کنید که در این مرحله، داکر شکست نخورده. جلوگیری از آسیبپذیریهایی مثل تزریق SQL، تزریق دستور یا سریالزدایی ناامن، وظیفه خود برنامه است، نه runtime کانتینر. نقش داکر از جایی شروع میشود که برنامه قبلاً به خطر افتاده.
اهداف مهاجم میتواند شامل این موارد باشد:
- خواندن دادههای حساس مثل کلیدهای API، اعتبارنامهها یا اسرار متصل شده.
- تغییر برنامه یا پیکربندی آن.
- ایجاد پایداری (persistence) طوری که دسترسی بعد از راهاندازی مجدد برنامه هم باقی بماند.
- افزایش سطح دسترسی در داخل کانتینر.
- فرار از کانتینر و به خطر انداختن میزبان.
- دسترسی یا دخالت در سایر کانتینرها.
- مصرف بیش از حد منابع سیستم برای ایجاد اختلال در سرویس.
هدف سختسازی کانتینر این است که تواناییهای مهاجم را بعد از یک نفوذ موفق محدود کند و انجام هر کدام از این اهداف را دشوارتر یا در حالت ایدهآل، غیرممکن بسازد.
یک مثال واقعی
این یک سناریوی فرضی نیست. هر سال آسیبپذیریهای حیاتی از نوع اجرای کد از راه دور در برنامههای کانتینری شده کشف میشود.
یک مثال اخیر، آسیبپذیری React Server Components (CVE-2025-55182) بود که روی برنامههای Next.js هم تأثیر گذاشت (اول با شناسه CVE-2025-66478 برای Next.js ردیابی شد). تحت شرایط خاص، یک مهاجم تأیید نشده میتوانست با فرستادن یک درخواست HTTP دستکاری شده به یک برنامه آسیبپذیر، کد دلخواه روی سرور اجرا کند.
فرض کنید برنامه شما داخل یک کانتینر داکر اجرا میشود و مهاجم با موفقیت از این آسیبپذیری استفاده کرده و در فرآیند برنامه به اجرای کد رسیده.
حالا از خودتان بپرسید:
- آیا میتوانند برنامه را تغییر دهند؟
- آیا میتوانند اسرار متصل شده را بدزدند؟
- آیا میتوانند پایداری ایجاد کنند؟
- آیا میتوانند به کانتینرهای دیگر دسترسی پیدا کنند؟
- آیا میتوانند به میزبان فرار کنند؟
- آیا میتوانند منابع میزبان را تمام کنند؟
ویژگیهای امنیتی داکر برای پاسخ به همین سؤالها طراحی شدهاند. سختسازی کانتینر ربطی به جلوگیری از آسیبپذیری اولیه ندارد. آن وظیفه به عهده برنامه و وابستگیهایش است. هدف اصلی این است که محدود کنیم مهاجم بعد از بهدستآوردن اجرای کد چه کارهایی میتواند بکند.
مرز امنیتی داکر
برای اینکه بفهمید داکر از چه چیزهایی میتواند محافظت کند و از چه چیزهایی نمیتواند، اول باید جایگاه داکر را در پشته سیستم مشخص کنید.
دامنه مسئولیت داکر از لایه Docker Engine شروع میشود و تا لایه Container ادامه پیدا میکند. داکر چرخه عمر کانتینرها را مدیریت میکند، namespaceها را تنظیم میکند، مجموعه قابلیتها را اعمال میکند، پروفایلهای seccomp را پیکربندی میکند، LSMها را وصل میکند و cgroupها را مدیریت میکند.
چیزی که داکر انجام نمیدهد، ایجاد یک مرز امنیتی در برابر هسته لینوکس است. هسته بین همه کانتینرهای روی میزبان مشترک است. داکر فقط مکانیزمهای امنیتی هسته را پیکربندی میکند؛ یک لایه امنیتی جدید روی آنها اضافه نمیکند.
این تمایز خیلی مهم است:
داکر یک مرز امنیتی در برابر آسیبپذیریهای هسته نیست.
اگر در یک زیرسیستم هسته، OverlayFS، eBPF، netfilter، io_uring یا هر زیرسیستم دیگری آسیبپذیری وجود داشته باشد، مهاجمی که میتواند با آن زیرسیستم تعامل کند، میتواند کاملاً از انزوای داکر عبور کند. اینها مشکل پیکربندی نیستند؛ باگ هستهاند و داکر نمیتواند وصلهشان کند. بسیاری از فرارهای خطرناک از کانتینر در سالهای اخیر از آسیبپذیریهای هسته استفاده کردهاند، نه از نقصهای پیکربندی داکر.
این حرف به این معنی نیست که داکر ناامن است. یعنی امنیت کانتینر در نهایت به امنیت لینوکس برمیگردد. برای درک نقاط قوت و محدودیتهای داکر، باید مکانیزمهای هستهای را که داکر به آنها تکیه میکند بشناسید.
در ادامه مقاله، میبینیم که چطور ویژگیهای مختلف داکر مثل اجرا با کاربر غیرروت، حذف قابلیتهای لینوکس، استفاده از فایلسیستم فقطخواندنی، فعالسازی seccomp و اعمال سیاستهای AppArmor یا SELinux با هم کار میکنند تا تأثیر یک نفوذ موفق را کاهش دهند. این مکانیزمها بهجای جلوگیری از همه حملات، طراحی شدهاند تا وقتی مهاجم ناگزیر وارد میشود، دامنه خسارت را محدود کنند.
اجرای کانتینرها با کاربر غیرروت
یکی از اولین توصیههایی که تقریباً در هر راهنمای امنیتی داکر میبینید این است:
کانتینرهایتان را با کاربر روت اجرا نکنید.
توصیه خوبی است، اما متأسفانه یکی از بدفهمترینها هم هست. یک سؤال رایج که توسعهدهندهها میپرسند:
اگر کانتینرها از قبل ایزوله هستند، چه فرقی میکند برنامه من با کاربر روت اجرا شود؟
جواب کوتاه: روت داخل کانتینر با روت روی میزبان یکی نیست، اما همچنان خیلی پرامتیازتر از یک کاربر معمولی داخل همان کانتینر است.
درک این تفاوت کلید فهم این است که چرا اجرا با کاربر غیرروت یکی از اصول اولیه سختسازی کانتینر محسوب میشود.
روت داخل کانتینر، روت میزبان نیست
در یک سیستم لینوکس سنتی، کاربر روت (UID 0) دسترسی نامحدودی به تقریباً همه بخشهای سیستم عامل دارد. کانتینرها این مدل را عوض میکنند.
فرآیندهای داخل یک کانتینر همچنان یک شناسه کاربر دارند. اگر آن کاربر root (UID 0) باشد، در داخل namespace کاربری کانتینر بهعنوان روت شناخته میشود. اما داکر چندین مکانیزم امنیتی مختلف را اعمال میکند - از جمله قابلیتهای لینوکس، namespaceها، seccomp و ماژولهای امنیتی لینوکس (AppArmor یا SELinux) - که جلوی بسیاری از امتیازاتی را که روت میزبان معمولاً دارد میگیرد.
مثلاً یک فرآیند روت داخل یک کانتینر پیشفرض داکر نمیتواند:
- ماژولهای هسته را بارگذاری کند.
- فایلسیستمهای دلخواه را mount کند.
- پارامترهای هسته را تغییر دهد.
- ساعت سیستم را عوض کند.
- فرآیندهای دلخواه میزبان را بازرسی یا کنترل کند.
این عملیات به امتیازاتی نیاز دارند که داکر عمداً حذف یا محدودشان کرده. پس روت کانتینر با روت میزبان برابر نیست، اما همچنان پرامتیازترین کاربر داخل کانتینر است.
چرا کوبرنتیز runAsNonRoot را توصیه میکند
اگر برنامههایتان را روی کوبرنتیز مستقر کرده باشید، احتمالاً با securityContext زیر برخورد کردهاید:
securityContext:
runAsNonRoot: true
این تنظیم به kubelet میگوید که بررسی کند کانتینر با UID 0 شروع نشود. اگر ایمیج طوری پیکربندی شده که با روت اجرا شود، کوبرنتیز از شروع کانتینر جلوگیری میکند. دلیل این تصمیم، بیاعتمادی کوبرنتیز به ایزولیشن داکر نیست. بیشتر برنامهها برای سرویسدهی درخواستهای HTTP، پردازش کارها یا ارتباط با پایگاه داده به امتیازات روت نیاز ندارند. اجرایشان بهعنوان یک کاربر بیامتیاز، یک دسته کامل از تکنیکهای پس از بهرهبرداری را با هزینه عملیاتی بسیار کم حذف میکند.
فرارهای کانتینر و چرا اهمیت دارند
شاید بپرسید:
اگر روت داخل کانتینر روت واقعی نیست، پس چرا باید برایم مهم باشد؟
چون فرار از کانتینر وجود دارد.
هرچند نادر است، اما آسیبپذیریهایی در هسته لینوکس یا زمان اجرای کانتینر گاهی به مهاجم اجازه داده از کانتینر خارج شود و روی میزبان کد اجرا کند. اگر فرآیند آلوده از قبل امتیازات زیادی داشته باشد، بهرهبرداری از این آسیبپذیریها خیلی راحتتر یا تأثیرگذارتر میشود. اجرای برنامهها با کاربر غیرروت احتمال فرار از کانتینر را به صفر نمیرساند، اما امتیازات مهاجم را در صورت وقوع محدود میکند.
از نظر تاریخی، بسیاری از فرارهای خطرناک کانتینر اصلاً از پیکربندی داکر عبور نکردهاند؛ مستقیماً از آسیبپذیریهای هسته استفاده کردهاند. مهاجمان از نقصهای OverlayFS سوءاستفاده کردهاند، از eBPF برای افزایش امتیاز استفاده کردهاند، netfilter و nftables را برای رسیدن به کد هسته دستکاری کردهاند و از io_uring برای خواندن/نوشتن دلخواه بهره بردهاند. در همه این موارد، مهاجم نیازی به شکستن داکر نداشت؛ باید لینوکس را میشکست. برای مثال، CVE-2023-0386 یک فرار از کانتینر در فایلسیستم OverlayFS کرنل لینوکس بود که به مهاجم بیامتیاز اجازه میداد با mount کردن یک فایلسیستم دستکاری شده در داخل کانتینر، دسترسی روت روی میزبان به دست آورد.
به همین دلیل هر لایه سختسازی هسته اهمیت دارد - هر کدام یک سطح حمله بالقوه را حذف میکند که یک اکسپلویت میتواند هدف قرار دهد.
User Namespaces
تا اینجا پیکربندی پیشفرض داکر را فرض کردیم، جایی که UID 0 داخل کانتینر مستقیم به UID 0 روی میزبان نگاشت میشود. لینوکس user namespaces را هم فراهم میکند که به شناسههای کاربر کانتینر اجازه میدهد دوباره نگاشت شوند. این یکی از قویترین راهکارها برای کاهش تأثیر فرار از کانتینر است و بهتر است بهعنوان یک مکانیزم امنیتی درجه یک جدی گرفته شود، نه یک افزونه اختیاری.
نحوه کار نگاشت مجدد به این شکل است:
| داخل کانتینر | روی میزبان |
|---|---|
| UID 0 (root) | UID 100000 |
| UID 1 | UID 100001 |
| UID 1000 | UID 101000 |
از دید کانتینر، برنامه همچنان با روت اجرا میشود. اما از دید میزبان، آن فرآیند فقط یک کاربر بیامتیاز معمولی است. این تفاوت ماهیت تأثیر فرار از کانتینر را عوض میکند.
حالا فرض کنید مهاجم یک آسیبپذیری هسته پیدا کرده که به آن اجازه میدهد خارج از namespaceهای کانتینر کد اجرا کند. بدون user namespaces، فرآیند فرار کرده UID 0 را روی میزبان حفظ میکند - یعنی مهاجم از همان اول دسترسی روت به سیستم دارد. با user namespaces فعال، فرآیند فرار کرده UID 100000 است، یک کاربر معمولی بیامتیاز. مهاجم از کانتینر فرار کرده اما هیچ امتیاز اضافهای روی میزبان ندارد.
قابلیتها، seccomp و LSMها همه محدود میکنند که یک فرآیند چه کاری میتواند انجام دهد. اما user namespaces هویت اصلی خود فرآیند را محدود میکند. مهاجمی که از namespace کانتینر فرار میکند، هنوز باید یک آسیبپذیری جداگانه برای افزایش امتیاز روی میزبان پیدا کند. این یعنی مهاجم دیگر فقط با «فرار از کانتینر» به هدفش نمیرسد؛ حالا باید «از کانتینر فرار کند و بعد میزبان را هم به خطر بیندازد».
با وجود این همه تأثیرگذاری، user namespaces در بسیاری از نصبهای داکر بهطور پیشفرض فعال نیست. دلیل اصلی سازگاری است: bind mountها، نگاشت مالکیت فایل و برخی storage backendها وقتی UIDها دوباره نگاشت میشوند رفتار متفاوتی دارند. بعضی ایمیجها فرض میکنند میتوانند فایلهایی را که بهعنوان روت مینویسند روی میزبان هم مالک روت باشند، که با نگاشت مجدد user namespace خراب میشود. این مشکلات قابل حل هستند، اما نیاز به پیکربندی و آزمایش دارند که خیلی از استقرارها روی آن سرمایهگذاری نمیکنند.
برای محیطهای تولیدی با الزامات امنیتی بالا، فعالسازی user namespaces باید اولویت داشته باشد. حفاظتی که در برابر تأثیر فرار کانتینر فراهم میکنند بهسختی با هر مکانیزم دیگری به تنهایی قابل دستیابی است.
قابلیتهای لینوکس
اگر اجرای کانتینرها با کاربر غیرروت اولین قدم برای کاهش امتیازات است، قابلیتهای لینوکس دومین قدم هستند.
در واقع، حتی اگر برنامه شما بهعنوان روت داخل یک کانتینر اجرا شود، باز هم امتیازات یک روت در سیستم لینوکس سنتی را ندارد. دلیلش این است که لینوکس مدرن دیگر روت را یک مفهوم همهیا-هیچ نمیبیند. در عوض، عملیات ممتاز را به مجموعهای از قابلیتهای مجزا تقسیم کرده.
چرا لینوکس روت را خرد کرد
از نظر تاریخی، یونیکس فقط دو سطح امتیاز داشت:
- روت (UID 0): دسترسی نامحدود به سیستم.
- بقیه: دسترسی محدود.
این مدل ساده بود، اما خیلی درشتدانه. یک سرور وب مثل Nginx را در نظر بگیرید. باید به پورت 80 متصل شود، اما نیازی به بارگذاری ماژولهای هسته، تغییر ساعت سیستم یا راهاندازی مجدد ماشین ندارد.
در مدل مجوز سنتی یونیکس، راهی برای دادن فقط امتیاز اتصال به پورت ممتاز وجود نداشت. مجبور بودید فرآیند را با روت اجرا کنید، که قدرت بسیار بیشتری از حد نیاز به آن میداد.
قابلیتهای لینوکس این مشکل را با شکستن امتیازات روت به مجوزهای جداگانه حل میکنند. هر قابلیت نمایانگر یک عملیات ممتاز خاص است، و فرآیندها فقط مجوزهایی را که واقعاً نیاز دارند دریافت میکنند.
مثلاً:
| قابلیت | اجازه میدهد |
|---|---|
CAP_NET_BIND_SERVICE | اتصال به پورتهای زیر 1024 |
CAP_NET_ADMIN | پیکربندی رابطهای شبکه، جداول مسیریابی، قوانین فایروال و ... |
CAP_SYS_PTRACE | ردیابی یا اشکالزدایی سایر فرآیندها |
CAP_SYS_MODULE | بارگذاری و تخلیه ماژولهای هسته |
CAP_SYS_TIME | تغییر ساعت سیستم |
CAP_SYS_ADMIN | انجام طیف گستردهای از عملیات مدیریتی |
مجموعه قابلیت پیشفرض داکر
وقتی یک کانتینر را شروع میکنید، داکر همه قابلیتهای لینوکس را در اختیار کانتینر قرار نمیدهد. در عوض، زیرمجموعهای را در اختیارش قرار میدهد که بیشتر بارهای کاری رایج را پوشش میدهد، و قابلیتهای خیلی خطرناک را حذف میکند.
درک این نکته مهم است: مجموعه قابلیت پیشفرض داکر یک سیاست امنیتی دقیق و بهینه نیست. یک مصالحه بین سازگاری و امنیت است. نگهدارندگان داکر لیست قابلیتهای لینوکس را بررسی کرده و آنهایی را که قطعاً خطرناک بودند (CAP_SYS_MODULE, CAP_SYS_BOOT, CAP_SYS_TIME, CAP_SYS_ADMIN) حذف کردند و بقیه را که به نظر میرسید برای بارهای کاری رایج نسبتاً ایمن باشند نگه داشتند. نتیجه عمداً مجازکننده است - داکر ترجیح میدهد چیزی را نشکند تا اینکه کاربران را مجبور به اشکالزدایی کند.
میتوانید قابلیتهای یک فرآیند داخل کانتینر را ببینید:
docker run --rm alpine sh -c "
apk add --no-cache libcap >/dev/null
capsh --print
"
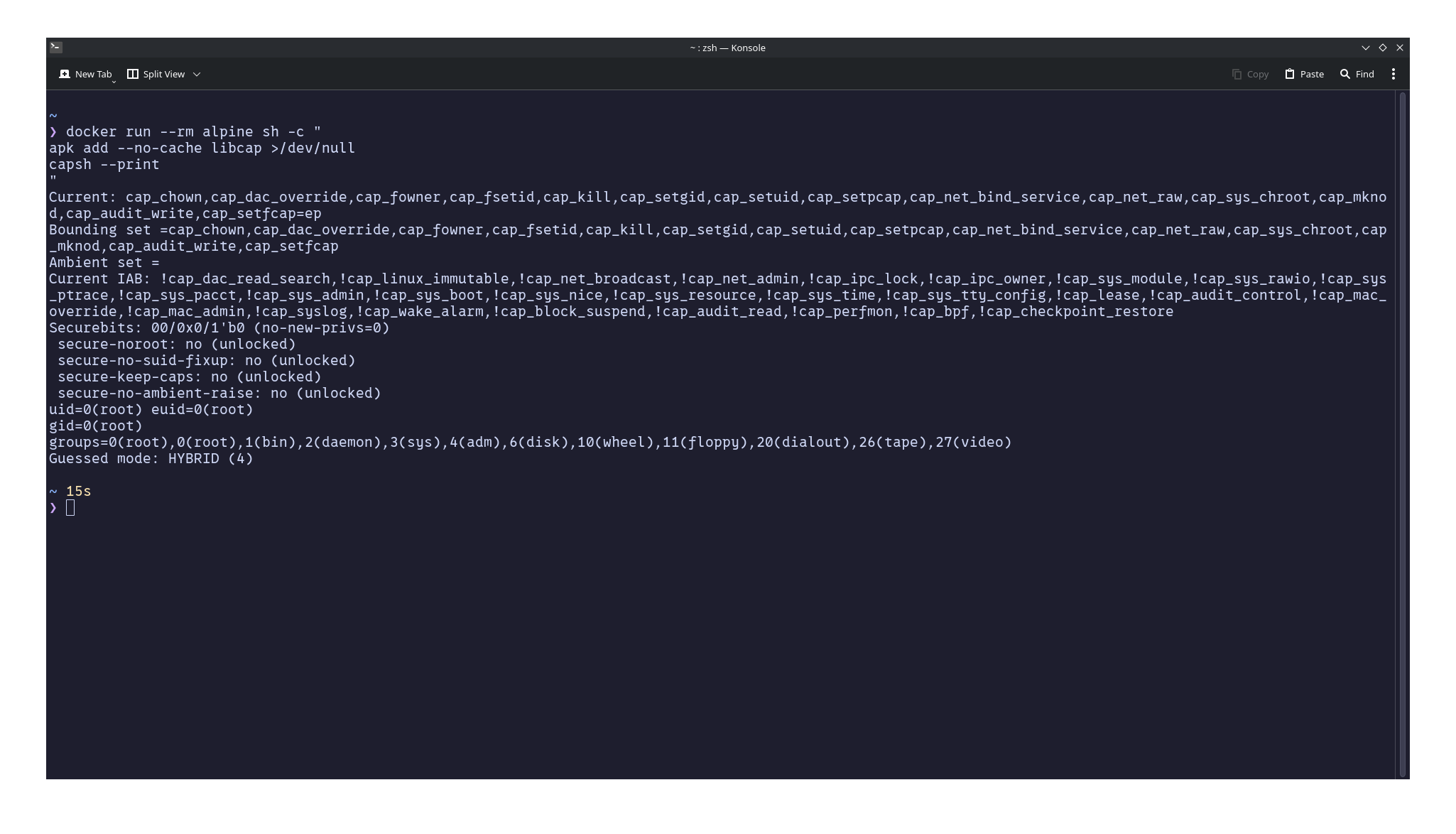
میبینید که قابلیتهایی مثل CAP_SYS_MODULE، CAP_SYS_BOOT، CAP_SYS_ADMIN و CAP_SYS_TIME غایب هستند. به همین دلیل یک فرآیند روت در کانتینر پیشفرض داکر نمیتواند خیلی از کارهایی را که روت میزبان میکند انجام دهد.
حذف قابلیتها با --cap-drop
داکر از قبل خیلی از قابلیتهای پرخطر را پیشفرض حذف کرده. دقت کنید که قابلیتهایی مثل CAP_SYS_ADMIN، CAP_SYS_MODULE، CAP_NET_ADMIN و CAP_SYS_PTRACE در مجموعه قابلیت کانتینر نیستند.
اما داکر هنوز یکسری قابلیت را میدهد که خیلی از برنامهها واقعاً نیاز ندارند. مثلاً یک برنامه Next.js معمولی نیازی به ایجاد گرههای دستگاه (CAP_MKNOD)، فرستادن بستههای خام شبکه (CAP_NET_RAW) یا تغییر مالکیت فایل (CAP_CHOWN) ندارد.
اینجاست که پرچم --cap-drop به کار میآید. بهجای اینکه فقط به مجموعه پیشفرض داکر تکیه کنید، میتوانید صریحاً قابلیتهایی را که نیاز ندارید حذف کنید.
برای شروع با مجموعه قابلیت خالی:
docker run --cap-drop ALL nginx
اگر دوباره فرآیند را با capsh --print بررسی کنید، میبینید که مجموعههای قابلیت مؤثر و bounding خالی شدهاند. فرآیند هنوز با UID 0 اجرا میشود، اما دیگر هیچ قابلیت لینوکسی فراتر از یک فرآیند معمولی بیامتیاز ندارد.
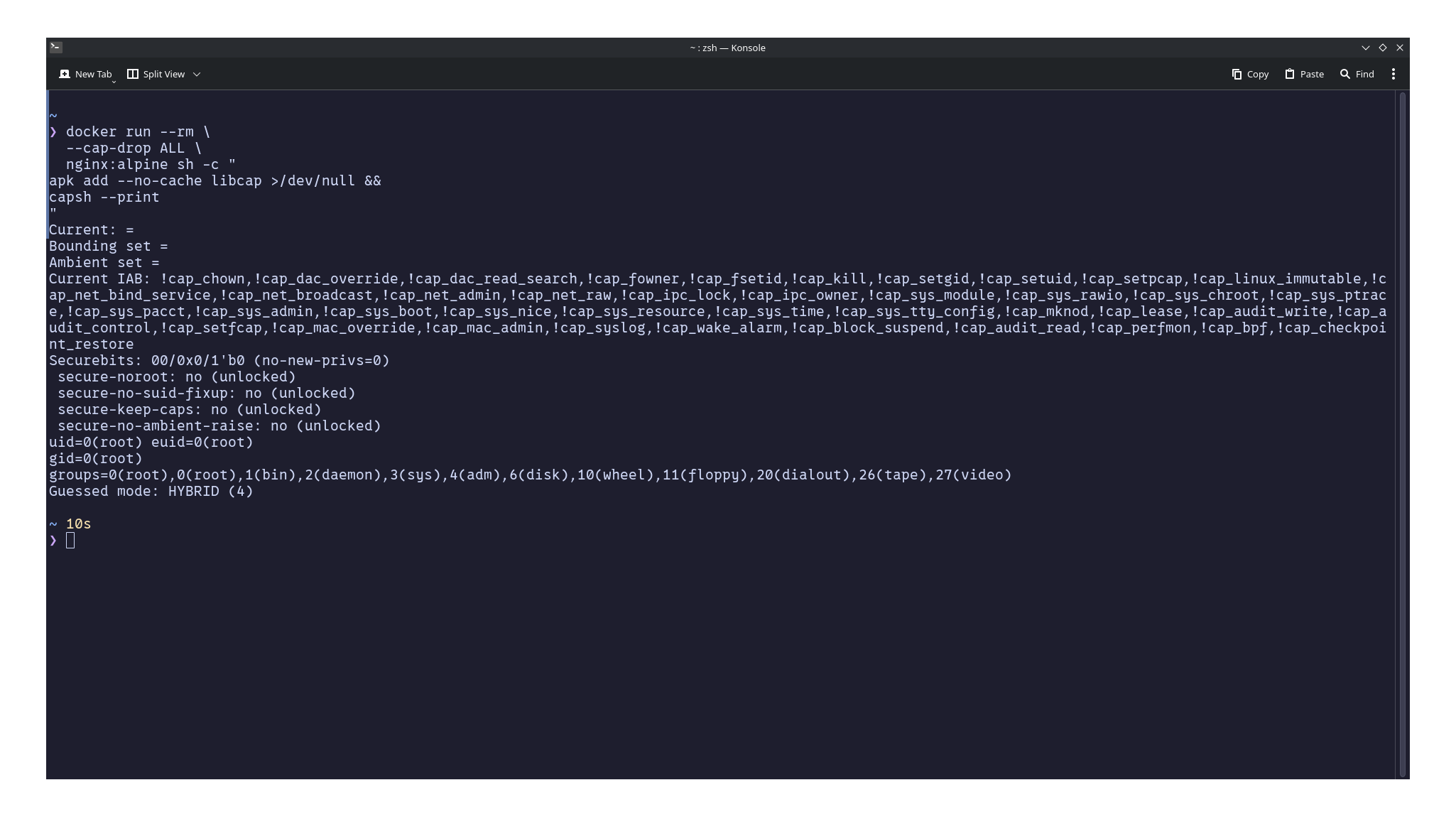
تفاوت دو خروجی را ببینید. در مثال اول، فرآیند با UID 0 (root) اجرا میشود و مجموعه قابلیت پیشفرض داکر را دارد، از جمله CAP_CHOWN، CAP_NET_BIND_SERVICE و CAP_SETFCAP. بعد از --cap-drop ALL، هر دو مجموعه Current و Bounding خالی میشوند، اما فرآیند هنوز با UID 0 (root) اجرا میشود. این به خوبی نشان میدهد که روت بودن به معنای ممتاز بودن نیست. یک فرآیند ممکن است شناسه کاربر 0 داشته باشد، اما بدون قابلیتهای لازم، هسته اجازه خیلی از عملیات را به آن نمیدهد.
در عمل، بیشتر برنامهها حداقل به یک یا دو قابلیت نیاز دارند. یک استراتژی رایج سختافزاری:
- اول همه قابلیتها را با
--cap-drop ALLحذف کنید. - برنامه را راه بیندازید.
- فقط قابلیتهای لازم برای عملکرد صحیح را اضافه کنید.
این رویکرد - یعنی دادن فقط مجوزهای مورد نیاز به فرآیند و نه بیشتر - همان اصل کمترین امتیاز (Principle of Least Privilege) در عمل است.
افزودن قابلیتها با --cap-add
فرض کنید Nginx را اجرا میکنید و میخواهید روی پورت 80 گوش دهد. اتصال به پورتهای ممتاز نیاز به CAP_NET_BIND_SERVICE دارد.
بهجای دادن امتیازات گسترده، فقط همان یک قابلیت را اضافه کنید:
docker run \
--cap-drop ALL \
--cap-add NET_BIND_SERVICE \
nginx
این کار خیلی امنتر از اجرای کانتینر با مجموعه پیشفرض داکر یا - بدتر از آن - استفاده از --privileged است.
چرا CAP_SYS_ADMIN «روت جدید» نامیده میشود
بین همه قابلیتهای لینوکس، یکی نیاز به توجه ویژه دارد:
CAP_SYS_ADMIN
اگر مستندات هسته یا security advisoryها را دنبال کرده باشید، حتماً این جمله را دیدهاید:
CAP_SYS_ADMINروت جدید است.
این لقب کاملاً بهجاست. برخلاف قابلیتهایی که یک امتیاز واحد و محدود میدهند، CAP_SYS_ADMIN کلی عملیات مدیریتی نامرتبط را پوشش میدهد.
فرآیندهای دارای این قابلیت میتوانند:
- فایلسیستمها را mount و unmount کنند.
- عملیات namespace را انجام دهند.
- رابطهای خاص هسته را پیکربندی کنند.
- عملیات ممتاز فایلسیستم را اجرا کنند.
- با eBPF و سایر ویژگیهای پیشرفته هسته تعامل داشته باشند (بسته به نسخه هسته).
در طول سالها، خیلی از آسیبپذیریهای هسته و تکنیکهای فرار کانتینر به CAP_SYS_ADMIN متکی بودهاند. پس اعطای این قابلیت باید با احتیاط شدید انجام شود. اگر برنامه شما صریحاً به آن نیاز ندارد، آن را اضافه نکنید.
CAP_NET_ADMIN: قدرتمندتر از چیزی که به نظر میرسد
یک قابلیت دیگر که معمولاً اشتباه درک میشود CAP_NET_ADMIN است. با وجود نامش، فقط اجازه مدیریت شبکه نمیدهد.
این قابلیت انواع مختلفی از عملیات ممتاز شبکه را فعال میکند، از جمله:
- ایجاد یا تغییر رابطهای شبکه.
- پیکربندی جداول مسیریابی.
- مدیریت قوانین فایروال.
- فعالسازی ارسال بسته.
- تغییر namespaceهای شبکه.
- پیکربندی کنترل ترافیک (tc).
این امتیازات برای نرمافزارهای شبکه مثل سرورهای VPN، پلاگینهای CNI یا کامپوننتهای شبکه تعریفشده توسط نرمافزار کاملاً منطقی است. اما برای یک برنامه وب معمولی تقریباً هرگز نیاز نیست. اگر به برنامهای که فقط HTTP سرویس میدهد CAP_NET_ADMIN بدهید، بیدلیل دامنه تأثیر یک نفوذ موفق را افزایش دادهاید.
مثال استفاده
فرض کنید یک برنامه Next.js را به محیط تولید میفرستید. بیشتر برنامههای Next.js پورتهای 80 یا 443 را مستقیماً expose نمیکنند. در عوض، روی یک پورت بیامتیاز مثل 3000 گوش میدهند و یک پروکسی معکوس مثل Nginx، Traefik یا HAProxy ترافیک HTTP و HTTPS را مدیریت میکند. در این سناریو، برنامه به هیچ قابلیت لینوکسی نیاز ندارد.
Docker Compose:
services:
nextjs:
image: my-nextjs-app:latest
cap_drop:
- ALL
Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nextjs
spec:
template:
spec:
containers:
- name: nextjs
image: my-nextjs-app:latest
securityContext:
capabilities:
drop:
- ALL
حالا تصور کنید مهاجم از آسیبپذیری Next.js که قبلاً گفتیم استفاده کرده و داخل کانتینر به اجرای کد رسیده.
خود اکسپلویت موفق میشود، اما فرآیند آلوده نمیتواند عملیات ممتاز هسته مثل ایجاد سوکت خام، پیکربندی رابطهای شبکه، بارگذاری ماژولهای هسته، mount فایلسیستم یا تغییر ساعت سیستم را انجام دهد - چون آن قابلیتها هرگز در اختیارش قرار نگرفته بودند.
اما اگر برنامه روی پورت 80 گوش دهد چه؟ بعضی برنامهها، مثل یک کانتینر Nginx که مستقیم روی میزبان اجرا میشود، روی پورتهای ممتاز مثل 80 یا 443 گوش میدهند. اتصال به پورتهای زیر 1024 نیاز به CAP_NET_BIND_SERVICE دارد.
در این موارد، فقط همان قابلیت خاص را بدهید، نه کل مجموعه پیشفرض داکر.
Docker Compose:
services:
nginx:
image: nginx:latest
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
template:
spec:
containers:
- name: nginx
image: nginx:latest
securityContext:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
چه Next.js، چه Nginx یا هر بار کاری دیگر، هدف یکی است: فقط قابلیتهایی را بدهید که برنامه واقعاً نیاز دارد. اگر به عملیات ممتاز هسته نیاز ندارد، ندهید. اگر دقیقاً یک قابلیت میخواهد، همان یک قابلیت را بدهید، و نه بیشتر.
فایلسیستمهای فقطخواندنی
بهطور پیشفرض، فایلسیستم ریشه کانتینر قابل نوشتن است. یعنی هر فرآیندی که داخل کانتینر اجرا میشود - از جمله فرآیندی که مهاجم کنترلش میکند - میتواند هر جا که مجوزهای فایلسیستم اجازه میدهد فایل ایجاد، تغییر یا حذف کند.
برای خیلی از برنامهها، این سطح دسترسی نوشتن اصلاً لازم نیست. یک سرور وب معمولاً کد برنامه را میخواند، به درخواستها جواب میدهد و دادههای موقتی مثل لاگ یا کش مینویسد. به ندرت پیش میآید که نیاز به تغییر باینریهای خودش یا کد منبع برنامه داشته باشد.
داکر به شما اجازه میدهد این فرض را با mount کردن فایلسیستم ریشه کانتینر به صورت فقطخواندنی اعمال کنید.
Docker:
docker run --read-only nginx
Docker Compose:
services:
app:
image: my-app:latest
read_only: true
Kubernetes:
securityContext:
readOnlyRootFilesystem: true
با فایلسیستم ریشه فقطخواندنی، هر تلاشی برای تغییر لایههای ایمیج کانتینر شکست میخورد - حتی اگر فرآیند مجوز فایل کافی داشته باشد. این کانتینر را به یک محیط اجرای غیرقابل تغییر تبدیل میکند که فایلهای برنامه بعد از راهاندازی قابل تغییر نیستند.
چرا فایلسیستم فقطخواندنی؟
وقتی مهاجم داخل کانتینر به اجرای کد رسید، یکی از اولین کارهایی که میکند تلاش برای ایجاد پایداری (persistence) است.
مثلاً ممکن است تلاش کند:
- برنامه را با یک نسخه تغییر یافته عوض کند.
- یک وب شل نصب کند.
- بدافزار اضافی دانلود کند.
- اسکریپتهای راهاندازی را تغییر دهد.
- ابزارهای سیستم را با نسخههای تروجانی جایگزین کند.
- درهای پشتی برای دسترسی آینده بگذارد.
با فایلسیستم قابل نوشتن، همه این کارها ممکن است - اگر مجوزهای فایلسیستم اجازه دهد. با فایلسیستم ریشه فقطخواندنی، این عملیات بلافاصله失敗 میخورد. مهاجم همچنان میتواند دستورات را در فرآیند آلوده اجرا کند، اما نمیتواند ایمیج کانتینر را دائماً تغییر دهد یا بدافزار پایدار در آن نصب کند.
ذخیرهسازی موقت با tmpfs
البته تعداد کمی از برنامهها کاملاً فقطخواندنی هستند. بیشتر آنها به جایی برای نوشتن فایلهای موقت نیاز دارند.
مثالها:
/tmp- سوکتهای زمان اجرا
- فایلهای PID
- آپلودهای موقت
- کش برنامه
بهجای اینکه کل فایلسیستم را قابل نوشتن کنید، داکر به این مکانها اجازه میدهد با یک فایلسیستم درونحافظه (tmpfs) پشتیبانی شوند.
Docker:
docker run --read-only --tmpfs /tmp my-nextjs-app:latest
Docker Compose:
services:
nextjs:
image: my-nextjs-app:latest
read_only: true
tmpfs:
- /tmp
Kubernetes:
volumes:
- name: tmp
emptyDir:
medium: Memory
containers:
- name: nextjs
volumeMounts:
- name: tmp
mountPath: /tmp
برخلاف فایلسیستم ریشه، یک mount tmpfs کاملاً در حافظه قرار دارد. هر چیزی که آنجا نوشته شود با توقف یا راهاندازی مجدد کانتینر ناپدید میشود. این به برنامهها یک مکان موقت میدهد بدون اینکه اجازه تغییرات دائمی داشته باشند.
مسیرهای قابل نوشتن باید صریح باشند
یکی از بزرگترین مزیتهای فعالسازی فایلسیستم فقطخواندنی این است که شما را مجبور میکند به این فکر کنید که برنامه کجا واقعاً به دسترسی نوشتن نیاز دارد. بهجای اجازه نوشتن در همه جا، صریحاً چند مکان محدود را که باید قابل نوشتن باقی بمانند مشخص میکنید.
مثلاً یک برنامه ممکن است به طور مشروع نیاز داشته باشد:
/tmpبرای فایلهای موقت./var/logاگر لاگها روی دیسک نوشته میشوند./uploadsبرای محتوای آپلودی کاربر.
بقیه چیزها میتوانند غیرقابل تغییر بمانند. این کار فرصتهای مهاجم برای تغییر برنامه یا ایجاد پایداری را به شدت کاهش میدهد.
کاهش بدافزار
مهم است که بفهمید فایلسیستم فقطخواندنی چه کار میکند و چه کار نمیکند. جلوی بهرهبرداری مهاجم از آسیبپذیری را نمیگیرد. جلوی اجرای کد دلخواه را هم نمیگیرد. در عوض، جلوی بسیاری از تکنیکهای رایج پس از بهرهبرداری را میگیرد.
مثلاً مهاجم دیگر نمیتواند:
- باینریهای برنامه را جایگزین کند.
- بدافزار را در فایلسیستم کانتینر دانلود کند.
- فایلهای پیکربندی را تغییر دهد.
- کرون جاب یا اسکریپت راهاندازی نصب کند.
- درهای پشتی پایدار داخل ایمیج کانتینر بگذارد.
کانتینرهای فقطخواندنی و زیرساخت غیرقابل تغییر
ایده فایلسیستم فقطخواندنی با یک اصل زیرساختی گستردهتر به نام زیرساخت غیرقابل تغییر (immutable infrastructure) هماهنگ است. در یک سیستم غیرقابل تغییر، بارهای کاری در حال اجرا هرگز در محل تغییر نمیکنند. اگر برنامه نیاز به بهروزرسانی دارد، SSH نمیزنید داخل کانتینر و فایلها را ویرایش نمیکنید - یک ایمیج جدید میسازید و یک کانتینر جدید مستقر میکنید.
به همین ترتیب، اگر کانتینری به خطر بیفتد، آن را تمیز یا تعمیر نمیکنید. آن را نابود کرده و با یک نمونه جدید از یک ایمیج مورد اعتماد جایگزینش میکنید.
این رویکرد استقرارها را قابل پیشبینیتر میکند، پاسخ به حادثه را سادهتر میکند و یک دسته کامل از مشکلات رانش پیکربندی را از بین میبرد.
فایلسیستم ریشه فقطخواندنی به طور طبیعی این فلسفه را تقویت میکند، چون تضمین میکند کانتینر در حال اجرا با ایمیجی که اول مستقر شده یکسان میماند.
جلوگیری از افزایش امتیاز با no-new-privileges
تا اینجا روی کاهش امتیازات اولیه کانتینر تمرکز کردیم. اما چه میشود اگر یک فرآیند بعد از شروع کار سعی کند امتیازات بیشتری به دست آورد؟
در سیستم لینوکس سنتی، چند مکانیزم به فرآیند اجازه میدهد امتیازاتش را در طول اجرا افزایش دهد. رایجترینشان باینریهای setuid و قابلیتهای فایل هستند.
برای جلوگیری از این نوع حملات، هسته لینوکس ویژگی No New Privileges (NNP) را فراهم کرده.
Docker:
docker run --security-opt no-new-privileges:true my-app:latest
Docker Compose:
services:
app:
image: my-app:latest
security_opt:
- no-new-privileges:true
Kubernetes:
securityContext:
allowPrivilegeEscalation: false
وقتی این ویژگی فعال باشد، هسته تضمین میکند که فرآیند نمیتواند امتیازاتی را که از قبل نداشته به دست آورد، مهم نیست چه برنامهای را اجرا کند. این no-new-privileges را به یکی از سادهترین و در عین حال مؤثرترین گزینههای سختافزاری تبدیل میکند.
درک setuid
فایلهای لینوکس میتوانند یک مجوز ویژه به نام بیت setuid داشته باشند. معمولاً یک برنامه با امتیازات کاربری که اجرایش میکند اجرا میشود. اما برنامه setuid با امتیازات مالک فایل اجرا میشود.
مثلاً ابزار passwd باید /etc/shadow را تغییر دهد - فایلی که فقط root میتواند در آن بنویسد. بهجای اینکه از هر کاربر بخواهد روت شود، لینوکس باینری را بهعنوان setuid علامتگذاری میکند تا بتواند موقتاً با امتیازات روت اجرا شود.
این مکانیزم خیلی مفید است، اما فرصتی برای افزایش امتیاز هم ایجاد میکند. اگر مهاجم بتواند یک باینری setuid آسیبپذیر اجرا کند، ممکن است امتیازاتی را که قبلاً نداشته به دست آورد.
با فعال بودن no-new-privileges، هسته بیت setuid را در طول اجرا نادیده میگیرد. برنامه اجرا میشود، اما امتیازات اضافی را به ارث نمیبرد.
قابلیتهای فایل (setcap)
قابلیتهای لینوکس فقط به فرآیندهای در حال اجرا اختصاص داده نمیشوند. میشود با ابزار setcap مستقیماً به فایلهای اجرایی وصلشان کرد.
مثلاً:
setcap cap_net_bind_service=+ep /usr/local/bin/my-server
این کار به فایل اجرایی اجازه میدهد بدون نیاز به روت به پورتهای ممتاز متصل شود. در شرایط عادی، اجرای این باینری قابلیت مشخص شده را به فرآیند میدهد.
اما وقتی no-new-privileges فعال است، آن قابلیتهای اضافی به دست نمیآیند - جلوی افزایش امتیاز از طریق قابلیتهای فایل هم گرفته میشود.
نقش execve()
هر دو setuid و قابلیتهای فایل موقع فراخوانی syscall execve() اعمال میشوند. هر بار که یک فرآیند لینوکس برنامه دیگری را اجرا میکند، هسته بررسی میکند که آیا باینری جدید باید امتیازات اضافی دریافت کند یا نه. معمولاً اینجا جایی است که افزایش امتیاز رخ میدهد.
با no-new-privileges، هسته قوانین را عوض میکند:
هیچ فرآیندی نمیتواند از طریق
execve()امتیازات بیشتری نسبت به قبل به دست آورد.
فرآیند میتواند برنامه دیگری اجرا کند، اما نمیتواند ممتازتر از قبل شود.
مثال: جلوگیری از افزایش امتیاز مبتنی بر Setuid
یک مثال واقعی از اینکه چرا no-new-privileges وجود دارد، آسیبپذیری PwnKit (CVE-2021-4034) است که در سال 2022 افشا شد.
این آسیبپذیری pkexec را هدف قرار داد، یک ابزار setuid-root که پیشفرض روی خیلی از توزیعهای لینوکس نصب است. از آنجایی که pkexec با امتیازات مالکش (root) اجرا میشود، یک نقص در پیادهسازیاش به یک کاربر محلی بیامتیاز اجازه میداد شل روت بگیرد.
تصور کنید برنامه آسیبپذیر Next.js ما به خطر افتاده و مهاجم داخل کانتینر اجرای دستور دارد. در مرحله شناسایی، یک باینری pkexec آسیبپذیر پیدا میکند و سعی میکند از آن بهرهبرداری کند.
بدون no-new-privileges، هسته بیت setuid را در execve() اجرا میکند. اگر اکسپلویت موفق شود، مهاجم یک شل با کاربر root میگیرد. با no-new-privileges فعال، نتیجه فرق میکند.
مهاجم همچنان میتواند pkexec را اجرا کند، اما هسته امتیازات اضافی مرتبط با بیت setuid را نمیدهد. فرآیند با امتیازات موجود مهاجم ادامه میدهد و این مسیر خاص افزایش امتیاز مسدود میشود.
نکته مهم: no-new-privileges یک دفاع همهجانبه در برابر همه آسیبپذیریهای افزایش امتیاز محلی نیست. این ویژگی مخصوصاً از بهدستآوردن امتیازات جدید از طریق فایلهای اجرایی setuid و قابلیتهای فایل در execve() جلوگیری میکند.
Seccomp: محدود کردن syscallها
حتی بعد از حذف قابلیتهای غیرضروری و جلوگیری از افزایش امتیاز، یک فرآیند آلوده هنوز میتواند syscallهای لینوکس را صدا بزند.
هر تعاملی بین فضای کاربر و هسته لینوکس در نهایت از طریق یک syscall (فراخوان سیستمی) انجام میشود.
خواندن یک فایل. باز کردن یک سوکت. ایجاد یک فرآیند. تخصیص حافظه. همه این عملیات در نهایت به یک syscall ختم میشوند.
Seccomp به ما اجازه میدهد کنترل کنیم که یک فرآیند مجاز به فراخوانی کدام syscallهاست. لینوکس مدرن صدها syscall دارد: mount()، bpf()، ptrace() - رابطهای قدرتمند هسته که بیشتر برنامهها هرگز به آنها نیاز ندارند.
پروفایل seccomp پیشفرض داکر
داکر بهطور پیشفرض برای هر کانتینر یک پروفایل seccomp اعمال میکند.
بهجای اجازه دسترسی نامحدود به هسته، داکر تعدادی از syscallهای پرخطر را که به ندرت توسط برنامههای معمولی نیاز میشوند مسدود میکند. مثالها شامل عملیات اشکالزدایی هسته، بارگذاری ماژولهای هسته، بعضی عملیات namespace و رابطهای قدیمی یا خطرناک هسته است.
مهم است که بفهمید این پروفایل پیشفرض چیست و چیست نیست. پروفایل seccomp پیشفرض داکر نسبتاً مجازکننده است. syscallهایی را که قطعاً خطرناک هستند یا تقریباً در کانتینرها نیاز نمیشوند مسدود میکند، اما یک لیست سفید سختگیرانه نیست. بیشتر syscallها همچنان مجازند. این طراحی عمدی است - اگر پیشفرض محدودکنندهتر بود، بسیاری از بارهای کاری قانونی را میشکست.
در محیطهای با امنیت بالا، پروفایل پیشفرض را باید بهعنوان نقطه شروع ببینید، نه پیکربندی نهایی. پروفایلهای سفارشی که فقط syscallهای مورد نیاز برنامه را لیست سفید میکنند، حفاظت خیلی قویتری دارند.
syscallهای خطرناک
بسیاری از آسیبپذیریهای تاریخی لینوکس شامل syscallهای ممتاز یا پیچیده بودهاند. چند مثال:
ptrace()برای اشکالزدایی فرآیندهای دیگر.mount()برای دستکاری فایلسیستمها.bpf()برای تعامل با زیرسیستم eBPF.userfaultfd()که در چندین آسیبپذیری افزایش امتیاز نقش داشته.- بعضی syscallهای مرتبط با namespace.
این رابطها فوقالعاده قدرتمندند و برای اکثریت قریب به اتفاق برنامههای وب غیرضروری. مسدود کردنشان یک دسته کامل از تکنیکهای پس از بهرهبرداری را حذف میکند.
پروفایلهای seccomp سفارشی
پروفایل seccomp پیشفرض داکر عمداً عمومی است. برای بیشتر بارهای کاری خوب کار میکند، اما محیطهای با امنیت بالا اغلب با تعریف پروفایلهای سفارشی متناسب با یک برنامه خاص جلوتر میروند.
مثلاً یک برنامه Next.js نیازهای syscall کاملاً متفاوتی با یک سرور VPN یا یک زمان اجرای کانتینر دارد.
یک پروفایل seccomp سفارشی میتواند فقط syscallهایی را که برنامه واقعاً استفاده میکند لیست سفید کند و بقیه را رد کند.
مثال: مسدود کردن حملات سطح هسته
یک سرور API پایتون از طریق یک وابستگی آسیبپذیر به خطر میافتد. مهاجم به اجرای کد میرسد و سعی میکند از ptrace() برای تزریق به فرآیندهای دیگر یا bpf() برای تعامل با زیرسیستم eBPF استفاده کند.
اگر آن syscallها توسط پروفایل seccomp مسدود شده باشند، هسته بلافاصله درخواست را رد میکند.
مهاجم هنوز اجرای کد دارد، اما نمیتواند آزادانه به هر رابط هستهای روی سیستم دسترسی پیدا کند.
AppArmor و SELinux
تا اینجا قابلیتها (که عملیات ممتاز را کنترل میکنند) و seccomp (که syscallها را کنترل میکند) را پوشش دادیم. یک لایه سوم هم داریم: ماژولهای امنیتی لینوکس، یا LSMها.
AppArmor و SELinux دو LSM پراستقرار هستند. آنها به یک سؤال متفاوت از قابلیتها یا seccomp جواب میدهند:
حتی اگر فرآیند قابلیت مناسب و syscall مناسب را داشته باشد، به چه فایلها، دایرکتوریها، منابع شبکه و اشیاء دیگر میتواند دسترسی داشته باشد؟
قابلیتها تعریف میکنند یک فرآیند چه کاری میتواند بکند. Seccomp تعریف میکند کدام APIهای هسته را میتواند صدا بزند. LSMها تعریف میکنند به کدام اشیاء میتواند دست بزند.
LSMها چه کاری انجام میدهند
LSM یک چارچوب هسته است که به سیاستهای امنیتی اجازه میدهد روی هر عملیات حساس امنیتی اعمال شوند. هر بار که فرآیندی سعی میکند فایلی را باز کند، به سوکتی متصل شود یا به دایرکتوری دسترسی پیدا کند، LSM سیاستش را قبل از اجازه یا رد عملیات بررسی میکند.
AppArmor از سیاستهای مبتنی بر مسیر استفاده میکند. شما یک پروفایل مینویسید که میگوید «این باینری میتواند /etc/nginx/nginx.conf را بخواند اما نمیتواند در آن بنویسد» یا «این باینری اصلاً نمیتواند سوکت شبکه ایجاد کند.»
SELinux از سیاستهای مبتنی بر برچسب استفاده میکند. هر فرآیند و هر شی (فایل، سوکت، دستگاه و غیره) یک برچسب امنیتی میگیرد و سیاست تعیین میکند کدام فرآیندهای برچسبدار میتوانند به کدام اشیاء برچسبدار دسترسی داشته باشند. SELinux قدرتمندتر و پیچیدهتر است، به همین دلیل بیشتر در محیطهای دولتی و با امنیت بالا میبینیدش تا استقرارهای کانتینری عمومی.
نحوه استفاده داکر از LSMها
وقتی کانتینری را اجرا میکنید، داکر میتواند یک پروفایل AppArmor یا SELinux context به فرآیندهای کانتینر وصل کند. این یک لایه اضافی کنترل دسترسی فراتر از قابلیتها و seccomp فراهم میکند.
داکر یک پروفایل AppArmor پیشفرض برای کانتینرها دارد که دسترسی به مسیرهای حساس میزبان و منابع سیستم را محدود میکند. اگر AppArmor روی میزبان بارگذاری شده باشد، خودکار اعمال میشود.
پشتیبانی SELinux در داکر موجود است، اما نیاز دارد که میزبان SELinux را اجرا کند (بیشتر در سیستمهای RHEL/CentOS/Fedora) و پرچم selinux-enabled در دیمن داکر پیکربندی شده باشد.
چگونه قابلیتها، Seccomp و LSMها با هم کار میکنند
هر مکانیزم امنیتی لینوکس به یک سؤال متفاوت جواب میدهد. درک این تفاوت به شما کمک میکند سهم هر لایه را بهتر بفهمید:
- قابلیتها: «چه عملیات ممتازی میتوانم انجام دهم؟»
- Seccomp: «کدام APIهای هسته را میتوانم صدا بزنم؟»
- LSMها: «حتی اگر بتونم صدا بزنم، به چه اشیایی میتوانم دسترسی داشته باشم؟»
این لایهها مکمل هم هستند. یک فرآیند ممکن است CAP_NET_BIND_SERVICE داشته باشد (میتواند به پورتهای ممتاز متصل شود) و seccomp ممکن است syscall bind() را مجاز کند، اما یک پروفایل AppArmor همچنان میتواند جلوی اتصال به یک پورت یا رابط شبکه خاص را بگیرد. هر مکانیزم یک بعد متفاوت از تواناییهای فرآیند را محدود میکند.
هیچ کدام از این لایهها به تنهایی کافی نیستند. اما با هم، یک موضع دفاع در عمق ایجاد میکنند که مهاجم باید چندین محدودیت مستقل را دور بزند تا به اهدافش برسد.
داکر روتلس (Rootless Docker)
داکر روتلس، دیمن داکر و کانتینرها را بدون امتیازات روت روی میزبان اجرا میکند. این روی همان user namespaces که قبلاً بحث شد ساخته شده، اما فراتر میرود و خود دیمن داکر را هم بهعنوان یک کاربر بیامتیاز اجرا میکند.
تفاوت اصلی با نگاشت مجدد user namespace استاندارد در دامنهاش است. در داکر استاندارد با user namespaces، فقط فرآیندهای کانتینر دوباره نگاشت میشوند، در حالی که دیمن داکر هنوز با روت اجرا میشود. در حالت روتلس، کل پشته داکر - دیمن، containerd و runc - بدون امتیازات روت میزبان اجرا میشود.
داکر روتلس محدودیتهایی هم دارد. نمیتواند به پورتهای زیر 1024 متصل شود (اگرچه ابزارهایی مثل authbind یا redirectorها میتوانند این را دور بزنند)، پشتیبانی محدودی برای برخی درایورهای ذخیرهسازی دارد و با همه پیکربندیهای شبکه کار نمیکند.
برای محیطهایی که لایه اضافهای از انزوای سطح میزبان میخواهند، حالت روتلس گزینه ارزشمندی است. اما برای بیشتر استقرارهای تولیدی، ترکیب user namespaces استاندارد با سایر اقدامات سختافزاری که در این مقاله گفتیم حفاظت قابل توجهی فراهم میکند.
امنیت دیمن داکر
مدل امنیتی داکر فقط به کانتینرها محدود نمیشود. خود دیمن داکر یک مرز امنیتی حیاتی است.
گروه docker معادل روت است
در سیستمهایی که داکر نصب است، کاربران را میشود به گروه docker اضافه کرد تا دستورات داکر را بدون sudo اجرا کنند. این راحت است، اما یک پیامد امنیتی جدی دارد: عضویت در گروه docker عملاً معادل دسترسی روت روی میزبان است.
دلیلش ساده است. یک کاربر در گروه docker میتواند:
- کانتینرها را با هر قابلیتی، از جمله
--privilegedشروع کند. - هر دایرکتوری میزبان را با دسترسی کامل خواندن-نوشتن به یک کانتینر mount کند.
- مستقیماً به سوکت API داکر دسترسی پیدا کند.
- پیکربندی داکر را تغییر دهد.
یعنی هر فرآیندی - کانتینری شده یا نه - که به سوکت داکر دسترسی دارد، عملاً دسترسی روت به میزبان دارد.
mount کردن /var/run/docker.sock به داخل کانتینر
یک anti-pattern رایج در استقرارهای داکر، mount کردن سوکت داکر (/var/run/docker.sock) به داخل کانتینر است. این کار معمولاً برای این انجام میشود که کانتینر بتواند کانتینرهای دیگر را مدیریت کند، مثلاً یک عامل CI/CD یا ابزار مانیتورینگ.
services:
container-manager:
image: my-manager:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
mount کردن سوکت داکر به داخل کانتینر یعنی فرآیندهای آن کانتینر همان امتیازات یک کاربر در گروه docker را دارند. اگر مهاجم آن کانتینر را به خطر بیندازد، میتواند کانتینرهای جدید شروع کند، فایلسیستمهای دلخواه میزبان را mount کند و دسترسی کامل سطح میزبان را بگیرد - همه اینها بدون فرار از کانتینر.
اگر یک بار کاری نیاز به دسترسی داکر دارد، به جای آن از API داکر از طریق TLS با گواهی مشتری استفاده کنید، یا از یک پروکسی امنیتی که فقط عملیات API خاص مورد نیاز را expose میکند.
علاوه بر سوکت، خود دیمن داکر هم باید ایمن شود. فعالسازی TLS برای API داکر از دسترسی تأیید نشده جلوگیری میکند و لاگگیری حسابرسی به تشخیص فراخوانیهای API مشکوک کمک میکند. حالت روتلس و سختسازی عمیقتر دیمن را در یک مقاله بعدی پوشش میدهم.
سوءاستفاده از منابع
تا اینجا تمرکز کردیم روی این که مهاجم نتواند امتیازات بیشتری بگیرد یا سیستم را تغییر دهد. اما همه حملات درباره افزایش امتیاز نیستند.
گاهی مهاجم فقط میخواهد برنامه شما را از دسترس خارج کند.
تصور کنید برنامه آسیبپذیر Next.js ما به خطر افتاده. مهاجم بهجای تلاش برای فرار از کانتینر، یک حلقه بینهایت اجرا میکند، مدام حافظه تخصیص میدهد یا هزاران فرآیند فرزند میسازد.
این حملات به امتیازات بالا نیاز ندارند - فقط از منابع موجود کانتینر سوءاستفاده میکنند.
برای کاهش این نوع حملات، داکر به cgroups (گروههای کنترل) تکیه میکند و به مدیران اجازه میدهد روی CPU، حافظه و ایجاد فرآیند محدودیت بگذارند.
محدودیتهای حافظه
بدون محدودیت حافظه، یک کانتینر آلوده میتواند تمام RAM موجود روی میزبان را مصرف کند و روی همه بارهای کاری دیگر تأثیر بگذارد.
Docker Compose:
services:
nextjs:
image: my-nextjs-app
deploy:
resources:
limits:
memory: 512M
Kubernetes:
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
اگر فرآیند از حد مجاز بیشتر شود، قاتل Out-Of-Memory (OOM) لینوکس آن را خاتمه میدهد، بهجای اینکه اجازه دهد حافظه میزبان را تمام کند.
محدودیت فرآیند (pids_limit)
یک تکنیک رایج دیگر انکار سرویس، fork bomb است - فرآیندی که مدام فرآیند فرزند ایجاد میکند تا سیستم عامل دیگر نتواند جدید بسازد.
داکر به ما اجازه میدهد محدود کنیم که یک کانتینر چند فرآیند میتواند ایجاد کند.
services:
nextjs:
image: my-nextjs-app
pids_limit: 100
حتی اگر مهاجم به اجرای کد برسد، نمیتواند بیشتر از حد مجاز فرآیند ایجاد کند.
محدودیتهای CPU
تمام کردن CPU یک راه مستقیم دیگر برای مختل کردن سرویس است.
با محدودیتهای CPU، مطمئن میشویم که یک کانتینر نمیتواند پردازندههای میزبان را به طور کامل تصاحب کند.
Docker Compose:
services:
nextjs:
image: my-nextjs-app
deploy:
resources:
limits:
cpus: "1.0"
Kubernetes:
resources:
requests:
cpu: "500m"
limits:
cpu: "1"
این محدودیتها جلوی سوءاستفاده را نمیگیرند، بلکه آن را مهار میکنند.
دسترسی به دستگاه
بهطور پیشفرض، داکر کانتینرها را از سختافزار میزبان ایزوله میکند. این مهم است چون در لینوکس، بسیاری از منابع سختافزاری بهصورت فایل در /dev expose میشوند. دسترسی به یکی از این دستگاهها اغلب دسترسی مستقیم به یک رابط هستهای میدهد، پس دسترسی به دستگاه باید عمداً داده شود، نه پیشفرض.
مثالهای رایج:
- GPUهای NVIDIA برای هوش مصنوعی و استنتاج یادگیری ماشین.
/dev/net/tunبرای نرمافزار VPN مثل WireGuard یا OpenVPN.- ماژولهای امنیتی سختافزاری (HSM) برای مدیریت کلید رمزنگاری.
- دستگاههای USB یا سریال در استقرارهای صنعتی و IoT.
مثلاً یک کانتینر WireGuard نیاز به دسترسی به دستگاه TUN دارد:
services:
wireguard:
image: linuxserver/wireguard
devices:
- /dev/net/tun:/dev/net/tun
cap_add:
- NET_ADMIN
بهجای expose کردن کل سلسلهمراتب /dev یا اجرای کانتینر با --privileged، فقط دستگاههایی را که بار کاری شما نیاز دارد در اختیارش بگذارید.
دسترسی به دستگاه موضوع گستردهای است و دستگاههای دقیق بین بارهای کاری فرق میکند. نکته مهم حفظ کردن همه دستگاهها نیست، بلکه پیروی از همان اصلی است که در کل این مقاله دنبال کردیم: فقط آنچه را که برنامه واقعاً نیاز دارد expose کنید، و نه بیشتر.
داکر از ویژگیهای بیشتری هم پشتیبانی میکند که خارج از scope این مقاله است، از جمله مجوزهای دستگاه (r، w، m)، پشتیبانی GPU، رابط دستگاه کانتینر (CDI) و قوانین cgroup دستگاه. اگر بار کاری شما به پیکربندی پیشرفتهتری نیاز دارد، مستندات رسمی داکر منبع جامعی برای پرچم --device و گزینههای زمان اجرای مرتبط دارد:
https://docs.docker.com/reference/cli/docker/container/run/#device.
کانتینرهای ممتاز (Privileged)
تا اینجا چندین لایه از مدل امنیتی داکر را پوشش دادیم:
- اجرا با کاربر غیرروت.
- حذف قابلیتهای غیرضروری.
- فایلسیستم ریشه فقطخواندنی.
- جلوگیری از افزایش امتیاز.
- محدود کردن syscallها.
- محدود کردن منابع.
- expose کردن فقط دستگاههای مورد نیاز.
- پیکربندی LSMها.
پرچم --privileged عملاً بسیاری از این حفاظتها را دور میزند.
--privileged واقعاً چه کار میکند
اجرای کانتینر با --privileged خیلی فراتر از «دادن مجوزهای بیشتر» است. داکر تقریباً همه قابلیتهای لینوکس را به کانتینر میدهد، دسترسی گستردهای به دستگاههای میزبان فراهم میکند، محدودیتهای cgroup دستگاه را برمیدارد و چندین مکانیزم ایمنی پیشفرض زمان اجرا را غیرفعال میکند.
نتیجه کانتینری است که تقریباً مثل یک فرآیند معمولی که مستقیم روی میزبان اجرا میشود رفتار میکند.
چرا باید از آن اجتناب کنید
یک الگوی رایج عیبیابی این است:
کانتینر مجوز ندارد.
با
--privilegedاجراش کن.
هرچند این کار اغلب مشکل فوری را حل میکند، اما دهها مجوزی را هم میدهد که برنامه احتمالاً هیچوقت به آنها نیاز ندارد.
بهجایش نیاز خاص را شناسایی کنید:
- آیا برنامه به
CAP_NET_ADMINنیاز دارد؟ - آیا به دسترسی
/dev/net/tunنیاز دارد؟ - آیا به یک قابلیت واحد لینوکس نیاز دارد؟
دادن یک مجوز تقریباً همیشه بهتر از دادن همه مجوزهاست. بهعنوان یک قاعده کلی، --privileged را باید برای نرمافزارهای زیرساختی تخصصی مثل زمانهای اجرای کانتینر سطح پایین، ابزارهای اشکالزدایی یا ابزارهای مدیریت سختافزار نگه دارید - نه برای برنامههای وب معمولی، APIها یا کارگرهای پسزمینه.
اگر برنامه تولیدی شما به --privileged نیاز دارد، اول بفهمید چرا، بعد قبولش کنید.
جمعبندی نهایی
در این مقاله ویژگیهای امنیتی داکر را جداگانه بررسی کردیم. اما در عمل، این ویژگیها قرار نیست تنها استفاده شوند - مکمل هم هستند.
بیایید به مدل تهدید اول مقاله برگردیم.
یک مهاجم از آسیبپذیری در برنامه Next.js ما استفاده کرده و داخل کانتینر به اجرای کد از راه دور رسیده.
در این مرحله، همه اقدامات سختافزاری که گفتیم با هم کار میکنند:
- برنامه با کاربر غیرروت اجرا میشود.
- همه قابلیتهای غیرضروری لینوکس حذف شدهاند.
- فایلسیستم ریشه فقطخواندنی است.
- فایلهای موقت فقط به tmpfs نوشته میشوند.
- افزایش امتیاز غیرفعال است.
- کانتینر با محدودیتهای CPU، حافظه و PID محدود شده.
- فقط حداقل منابع مورد نیاز برنامه expose شده.
هیچ کدام از این اقدامات جلوی اکسپلویت اولیه را نمیگیرد. در عوض، با هم گزینههای مهاجم را بعد از نفوذ موفق محدود میکنند.
مثالهای زیر نشان میدهد که این پیکربندی برای یک برنامه Next.js آماده تولید که پشت پروکسی معکوس Nginx اجرا میشود چطور میتواند باشد.
Docker
docker network create web
docker run -d \
--name nextjs \
--network web \
--user 1000:1000 \
--read-only \
--tmpfs /tmp \
--cap-drop ALL \
--security-opt no-new-privileges:true \
--memory 512m \
--cpus 1 \
--pids-limit 100 \
my-nextjs-app:latest
docker run -d \
--name nginx \
--network web \
-p 80:80 \
--read-only \
--tmpfs /var/cache/nginx \
--tmpfs /var/run \
--cap-drop ALL \
--cap-add NET_BIND_SERVICE \
--security-opt no-new-privileges:true \
nginx:latest
Docker Compose
services:
nextjs:
image: my-nextjs-app:latest
user: "1000:1000"
read_only: true
tmpfs:
- /tmp
cap_drop:
- ALL
security_opt:
- no-new-privileges:true
pids_limit: 100
deploy:
resources:
limits:
cpus: "1.0"
memory: 512M
nginx:
image: nginx:latest
ports:
- "80:80"
read_only: true
tmpfs:
- /var/cache/nginx
- /var/run
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
security_opt:
- no-new-privileges:true
Kubernetes
apiVersion: apps/v1
kind: Deployment
metadata:
name: nextjs
spec:
replicas: 1
selector:
matchLabels:
app: nextjs
template:
metadata:
labels:
app: nextjs
spec:
containers:
- name: nextjs
image: my-nextjs-app:latest
securityContext:
runAsNonRoot: true
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
resources:
requests:
cpu: "250m"
memory: "256Mi"
limits:
cpu: "1"
memory: "512Mi"
volumeMounts:
- name: tmp
mountPath: /tmp
volumes:
- name: tmp
emptyDir:
medium: Memory
این مثالها برای کپی شدن مستقیم در هر محیط تولیدی نیستند - هر بار کاری نیازهای متفاوتی دارد. در عوض، ذهنیت امنیتی را نشان میدهند که در سراسر مقاله دنبال کردیم: امتیازاتی را که نیاز ندارید حذف کنید، فقط منابعی را که برنامه واقعاً نیاز دارد expose کنید، و فرض کنید برنامه ممکن است روزی به خطر بیفتد.
نتیجهگیری
امنیت داکر دفاع در عمق است، نه یک گلوله نقرهای. کاربران غیرروت، قابلیتها، فایلسیستمهای فقطخواندنی، no-new-privileges، seccomp، LSMها، cgroupها و محدودیتهای دستگاه - هر کدام بخشی از سطح حمله را حذف میکنند. هر کدام به تنهایی مفیدند، اما با هم کار پس از بهرهبرداری را به شدت دشوارتر میکنند.
داکر جلوی به خطر افتادن برنامه شما را نمیگیرد. کاری که میکند این است که محدود میکند مهاجم بعد از ورود چه کارهایی میتواند بکند. و این تمایز مهم است. هر مجوز غیرضروری، دایرکتوری قابل نوشتن یا دستگاه expose شده، فرصتی است که لازم نبود بدهید.
امنیت درباره غیرممکن کردن نفوذ نیست. درباره این است که وقتی اتفاق افتاد، مهاجم تا جایی که ممکن است گزینههای کمی داشته باشد.
این مقاله روی مکانیزمهای امنیتی زمان اجرای داکر متمرکز بود. اگر وقت کنم، ممکن است مقالات بعدی درباره امنیت زنجیره تأمین، مدیریت اسرار، سیاستهای شبکه و تشخیص زمان اجرا بنویسم.